
2025-06-15
Streaming Large files from SFTP to S3
Streaming large files directly from SFTP to S3 without any intermediate disk storage, using Python's asyncio

Streaming Large Files from SFTP to S3
Moving large files from SFTP servers to cloud storage is a common requirement in data engineering workflows. Traditional approaches often involve downloading files to local disk first, then uploading to S3 - a process that's slow, disk-intensive, and doesn't scale well. In this post, we'll explore how to stream files directly from SFTP to S3 without any intermediate disk storage, using Python's asyncio capabilities for optimal performance.
All code for this post is available on Github. Please consider giving it a star if you find it useful.
🔗 Source Code: abyssnlp/sftp-streaming-s3
Contents
- The Problem with Traditional File Transfer
- Architecture Overview
- Prerequisites
- Implementation Deep Dive
- Performance Tuning
- Monitoring and Observability
- Comparison with Traditional Approach
- Troubleshooting
- Conclusion
The Problem with Traditional File Transfer
Most file transfer solutions follow a simple but inefficient pattern:
- Download file from SFTP to local disk
- Upload file from local disk to S3
- Clean up local files
This approach has several drawbacks:
- Slow transfer: Sequential download then upload doubles the transfer time
- I/O bottlenecks: Heavy disk writes can impact system performance
- Disk and Memory inefficiency: Files must be fully downloaded before upload begins
- Poor scalability: Processing multiple large files quickly exhausts disk space
For data engineering workflows dealing with multi-gigabyte files, these limitations become critical bottlenecks. A better approach is to stream data directly from SFTP to S3, eliminating disk I/O entirely.
Architecture Overview
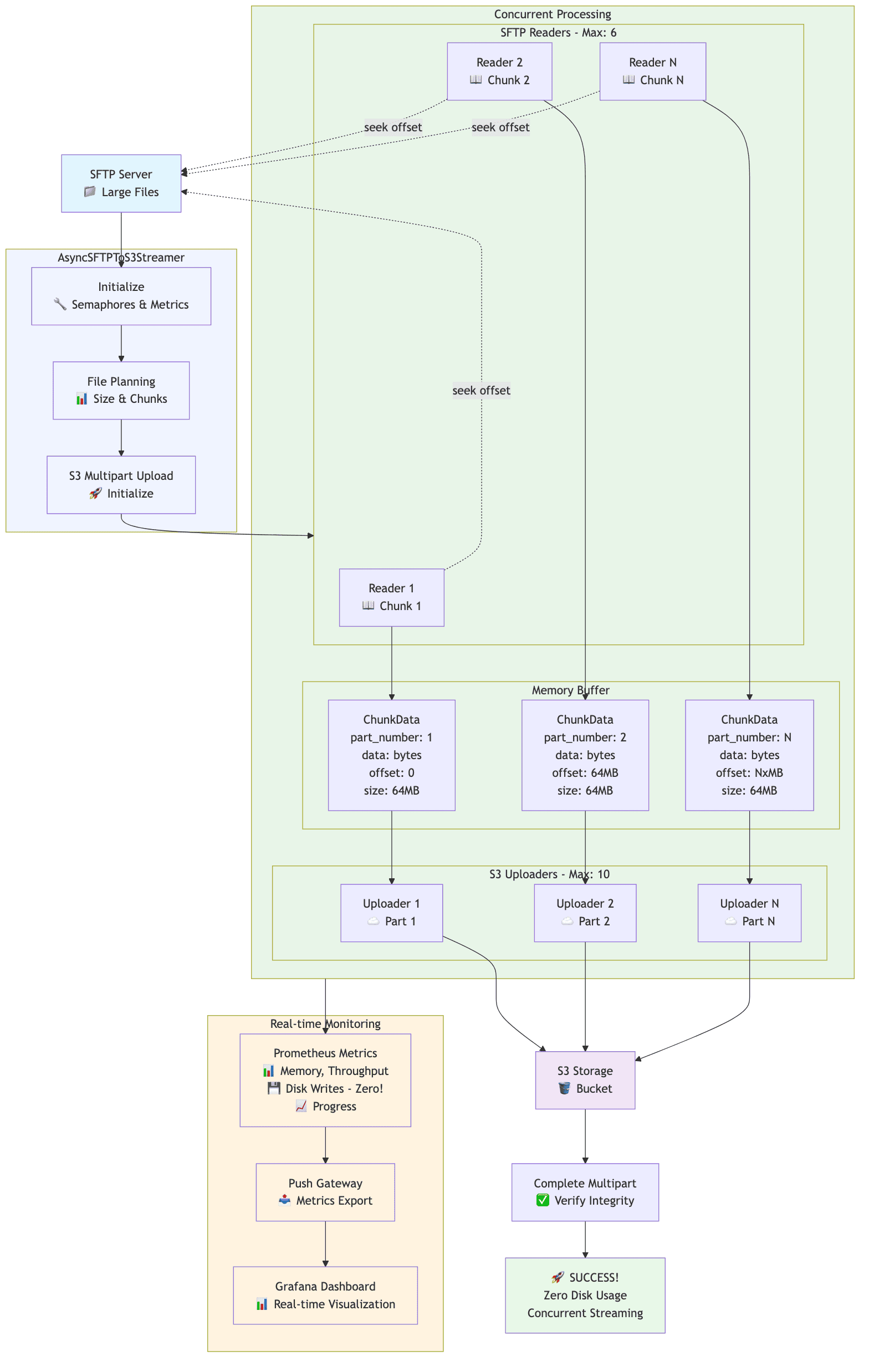
The key components are:
- Async SFTP Client: Reads file chunks asynchronously from remote servers using
asyncssh - Concurrent Processing: Multiple async workers read and upload chunks in parallel
- S3 Multipart Upload: Leverages S3's multipart upload API for optimal throughput
- Metrics Collection: Real-time monitoring of throughput, memory usage, and disk writes
Prerequisites
To follow along with this implementation, you'll need:
- Python 3.9+
- Poetry (for dependency management)
- Access to an SFTP server
- AWS S3 or S3-compatible storage (MinIO for local testing)
- Prometheus Push Gateway (optional, for metrics)
It is recommended to run services on a local Kubernetes cluster (eg. using Docker desktop) for testing. The manifests to setup the SFTP server, S3 MinIO server, Prometheus and Grafana are included in the repository.
Implementation Deep Dive
Core Streamer Class
The foundation of our streaming approach is the AsyncSFTPToS3Streamer class that orchestrates the entire process:
1@dataclass 2class ChunkData: 3 """Container for chunk data and metadata""" 4 part_number: int 5 data: bytes 6 offset: int 7 size: int 8 9class AsyncSFTPToS3Streamer: 10 CHUNK_SIZE: Final[int] = 64 * 1024 * 1024 # 64MB chunks 11 MAX_CONCURRENT_UPLOADS: Final[int] = 10 12 MAX_CONCURRENT_READS: Final[int] = 6 13 14 def __init__( 15 self, 16 bucket_name: str, 17 push_gateway_url: str, 18 job_name: str = "sftp-s3-streaming", 19 ssh_connection_params: Optional[Dict[str, Any]] = None, 20 s3_endpoint_url: str = "http://localhost:9000", 21 ): 22 self.bucket_name = bucket_name 23 self.push_gateway_url = push_gateway_url 24 self.job_name = job_name 25 self.s3_endpoint_url = s3_endpoint_url 26 self.ssh_connection_params = ssh_connection_params or {} 27 28 # Initialize metrics and process monitoring 29 self.registry = CollectorRegistry() 30 self.setup_metrics() 31 self.process = psutil.Process() 32 33 # Track initial I/O counters for disk write monitoring 34 try: 35 initial_io = self.process.io_counters() 36 self.initial_read_bytes = initial_io.read_bytes 37 self.initial_write_bytes = initial_io.write_bytes 38 except (psutil.NoSuchProcess, psutil.AccessDenied): 39 self.initial_read_bytes = 0 40 self.initial_write_bytes = 0 41 42 # Set up async clients and semaphores 43 self.s3_session = aioboto3.Session() 44 self.read_semaphore = asyncio.Semaphore(self.MAX_CONCURRENT_READS) 45 self.upload_semaphore = asyncio.Semaphore(self.MAX_CONCURRENT_UPLOADS) 46
The class uses semaphores to control concurrency and tracks initial I/O counters to verify zero-disk operation.
Async SFTP Operations
The SFTP operations are designed to create connections on-demand and read specific byte ranges. An optimized approach could be to create an SFTP connection pool to avoid the overhead of establishing connections for each chunk read. However, for simplicity, we will create a new connection for each read operation in this example.
1async def _create_sftp_connection(self): 2 """Create a new SFTP connection""" 3 try: 4 conn_params = self.ssh_connection_params.copy() 5 conn_params["known_hosts"] = None 6 conn = await asyncssh.connect(**conn_params) 7 sftp = await conn.start_sftp_client() 8 return sftp, conn 9 except Exception as e: 10 logger.error(f"Failed to create SFTP connection: {e}") 11 raise 12 13async def _read_chunk( 14 self, remote_path: str, part_number: int, offset: int, chunk_size: int 15) -> Optional[ChunkData]: 16 """Read a single chunk from SFTP""" 17 async with self.read_semaphore: 18 sftp, conn = None, None 19 try: 20 sftp, conn = await self._create_sftp_connection() 21 22 async with sftp.open(remote_path, "rb") as remote_file: 23 await remote_file.seek(offset) 24 data = await remote_file.read(chunk_size) 25 26 if not data: 27 return None 28 29 return ChunkData( 30 part_number=part_number, 31 data=data, 32 offset=offset, 33 size=len(data), 34 ) 35 36 except Exception as e: 37 logger.error(f"Error reading chunk {part_number}: {e}") 38 return None 39 finally: 40 if conn: 41 conn.close() 42
Each chunk read operation:
- Creates a dedicated SFTP connection to avoid blocking
- Seeks to the specific offset for parallel reading
- Reads exactly the required chunk size
- Properly cleans up connections to prevent resource leaks
Concurrent S3 Multipart Uploads
The S3 upload leverages multipart upload API for optimal performance:
1async def _upload_chunk( 2 self, upload_id: str, remote_path: str, chunk_data: ChunkData 3) -> Optional[Dict[str, Any]]: 4 """Upload a single chunk to S3""" 5 async with self.upload_semaphore: 6 try: 7 async with self.s3_session.client( 8 "s3", endpoint_url=self.s3_endpoint_url 9 ) as s3_client: 10 part = await s3_client.upload_part( 11 Bucket=self.bucket_name, 12 Key=remote_path, 13 PartNumber=chunk_data.part_number, 14 UploadId=upload_id, 15 Body=chunk_data.data, 16 ) 17 18 # Update metrics 19 self.bytes_transferred.inc(chunk_data.size) 20 self.chunks_processed.inc() 21 22 logger.debug( 23 f"Uploaded part {chunk_data.part_number} ({chunk_data.size} bytes)" 24 ) 25 26 return {"ETag": part["ETag"], "PartNumber": chunk_data.part_number} 27 28 except Exception as e: 29 logger.error(f"Error uploading chunk {chunk_data.part_number}: {e}") 30 return None 31 32async def _process_chunk( 33 self, 34 upload_id: str, 35 remote_path: str, 36 part_number: int, 37 offset: int, 38 chunk_size: int, 39) -> Optional[Dict[str, Any]]: 40 """Read and upload a single chunk""" 41 chunk_data = await self._read_chunk( 42 remote_path, part_number, offset, chunk_size 43 ) 44 if not chunk_data: 45 return None 46 47 return await self._upload_chunk(upload_id, remote_path, chunk_data) 48
The implementation combines reading and uploading into a single async operation, allowing for maximum parallelism.
Real-time Monitoring
Monitoring is crucial for validating zero-disk operation and tracking performance:
1def setup_metrics(self): 2 """Initialize simplified Prometheus metrics""" 3 self.memory_usage_mb = Gauge( 4 "sftp_s3_memory_usage_mb", 5 "Memory usage in MB during streaming", 6 registry=self.registry, 7 ) 8 self.process_write_bytes_mb = Gauge( 9 "sftp_s3_process_write_bytes_mb", 10 "Process write bytes in MB (indicates if process is writing to disk)", 11 registry=self.registry, 12 ) 13 self.bytes_transferred = Counter( 14 "sftp_s3_bytes_transferred_total", 15 "Total bytes transferred from SFTP to S3", 16 registry=self.registry, 17 ) 18 self.chunks_processed = Counter( 19 "sftp_s3_chunks_processed_total", 20 "Total chunks processed", 21 registry=self.registry, 22 ) 23 self.throughput_mbps = Gauge( 24 "sftp_s3_throughput_mbps", 25 "Current throughput in MB/s", 26 registry=self.registry, 27 ) 28 29def _update_metrics(self): 30 """Update system metrics""" 31 memory_mb = self.process.memory_info().rss / (1024 * 1024) 32 self.memory_usage_mb.set(memory_mb) 33 34 try: 35 current_io = self.process.io_counters() 36 write_bytes = current_io.write_bytes - self.initial_write_bytes 37 self.process_write_bytes_mb.set(write_bytes / (1024 * 1024)) 38 except (psutil.NoSuchProcess, psutil.AccessDenied): 39 self.process_write_bytes_mb.set(0) 40
The critical metric is process_write_bytes_mb which should remain near zero, proving that no disk buffering is occurring.
Main Upload Orchestration
The main upload method coordinates the entire streaming process:
1async def upload_to_s3(self, path: str) -> None: 2 """Main method to upload file from SFTP to S3""" 3 start_time = time.time() 4 5 # Get file size for planning 6 sftp, conn = await self._create_sftp_connection() 7 try: 8 file_stat = await sftp.stat(path) 9 file_size = file_stat.size or 0 10 logger.info( 11 f"File size: {file_size} bytes ({file_size / (1024*1024):.1f} MB)" 12 ) 13 finally: 14 conn.close() 15 16 total_chunks = (file_size + self.CHUNK_SIZE - 1) // self.CHUNK_SIZE 17 logger.info( 18 f"Starting transfer: {total_chunks} chunks of {self.CHUNK_SIZE // (1024*1024)}MB each" 19 ) 20 21 # Initialize multipart upload 22 async with self.s3_session.client( 23 "s3", endpoint_url=self.s3_endpoint_url 24 ) as s3_client: 25 upload_response = await s3_client.create_multipart_upload( 26 Bucket=self.bucket_name, Key=path 27 ) 28 upload_id = upload_response["UploadId"] 29 30 try: 31 # Create tasks for all chunks 32 tasks = [] 33 for i in range(total_chunks): 34 part_number = i + 1 35 offset = i * self.CHUNK_SIZE 36 chunk_size = min(self.CHUNK_SIZE, file_size - offset) 37 38 task = asyncio.create_task( 39 self._process_chunk( 40 upload_id, path, part_number, offset, chunk_size 41 ) 42 ) 43 tasks.append(task) 44 45 # Process chunks as they complete 46 parts = [] 47 completed = 0 48 49 for task in asyncio.as_completed(tasks): 50 result = await task 51 if result: 52 parts.append(result) 53 completed += 1 54 55 # Update metrics and progress 56 self._update_metrics() 57 58 progress = (completed / total_chunks) * 100 59 elapsed = time.time() - start_time 60 throughput = ( 61 (completed * self.CHUNK_SIZE / (1024 * 1024)) / elapsed 62 if elapsed > 0 63 else 0 64 ) 65 self.throughput_mbps.set(throughput) 66 67 if completed % 5 == 0 or completed == total_chunks: 68 logger.info( 69 f"Progress: {progress:.1f}% ({completed}/{total_chunks}) - {throughput:.1f} MB/s" 70 ) 71 await self._push_metrics() 72 73 # Complete multipart upload 74 parts.sort(key=lambda x: x["PartNumber"]) 75 76 async with self.s3_session.client( 77 "s3", endpoint_url=self.s3_endpoint_url 78 ) as s3_client: 79 await s3_client.complete_multipart_upload( 80 Bucket=self.bucket_name, 81 Key=path, 82 UploadId=upload_id, 83 MultipartUpload={"Parts": parts}, 84 ) 85 86 # Verify integrity and report results 87 s3_object = await s3_client.head_object(Bucket=self.bucket_name, Key=path) 88 s3_size = s3_object["ContentLength"] 89 90 integrity_ok = await self._verify_integrity(path, s3_size) 91 92 total_duration = time.time() - start_time 93 final_throughput = (file_size / (1024 * 1024)) / total_duration 94 95 self._update_metrics() 96 await self._push_metrics() 97 98 logger.info(f"🚀 UPLOAD COMPLETED! 🚀") 99 logger.info(f"File: {path} -> bucket {self.bucket_name}") 100 logger.info(f"Size: {file_size} bytes in {total_duration:.2f}s") 101 logger.info(f"Throughput: {final_throughput:.2f} MB/s") 102 logger.info(f"Memory usage: {self.memory_usage_mb._value._value:.1f} MB") 103 logger.info( 104 f"Process write bytes: {self.process_write_bytes_mb._value._value:.1f} MB" 105 ) 106 logger.info(f"Integrity: {'✓ VERIFIED' if integrity_ok else '✗ FAILED'}") 107 108 except Exception as e: 109 logger.error(f"Upload failed: {e}") 110 # Cleanup on failure 111 try: 112 async with self.s3_session.client( 113 "s3", endpoint_url=self.s3_endpoint_url 114 ) as s3_client: 115 await s3_client.abort_multipart_upload( 116 Bucket=self.bucket_name, Key=path, UploadId=upload_id 117 ) 118 except Exception: 119 pass 120 raise 121
The orchestration method uses asyncio.as_completed() to process chunks as they finish, providing real-time progress updates and metrics.
Performance Tuning
The streaming performance can be optimized by adjusting the class constants:
1# Configuration parameters for optimal performance 2CHUNK_SIZE: Final[int] = 64 * 1024 * 1024 # 64MB chunks 3MAX_CONCURRENT_UPLOADS: Final[int] = 10 # Number of parallel S3 uploads 4MAX_CONCURRENT_READS: Final[int] = 6 # Number of parallel SFTP reads 5
Tuning Guidelines:
Chunk Size:
- 64MB provides a good balance between memory usage and API efficiency
- Larger chunks reduce multipart upload overhead but increase memory requirements
- Smaller chunks provide better parallelism but more API calls
Concurrent Operations:
- The default 10 concurrent uploads work well for most S3 endpoints
- SFTP read concurrency is limited to 6 to avoid overwhelming the server
- Monitor connection pool exhaustion when increasing concurrency
Memory Usage:
- Total memory usage approximates:
CHUNK_SIZE * (MAX_CONCURRENT_READS + MAX_CONCURRENT_UPLOADS) - With defaults: ~64MB * 16 = ~1GB maximum memory usage
Monitoring and Observability
The repository includes a complete monitoring setup with Grafana dashboards:
Key Metrics Dashboard
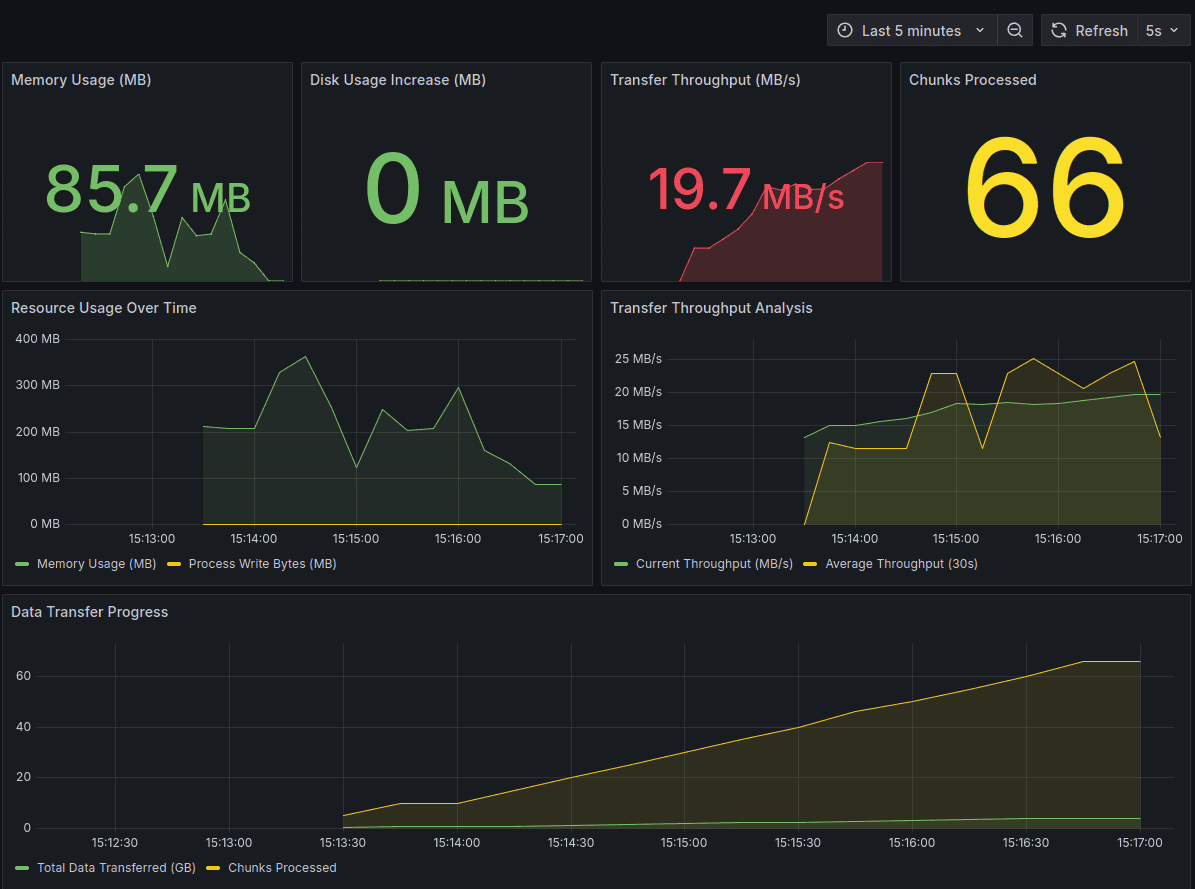
The dashboard tracks:
- Memory Usage (MB): Should remain stable throughout transfer
- Process Write Bytes (MB): Critical metric that validates zero-disk operation
- Transfer Throughput (MB/s): Real-time transfer speed
- Chunks Processed: Progress indicator showing completion rate
- Bytes Transferred: Total data moved from SFTP to S3
Zero-Disk Validation
The most important aspect of monitoring is confirming that the process truly streams without disk writes:
1# This metric should stay near 0 for true streaming 2current_io = self.process.io_counters() 3write_bytes = current_io.write_bytes - self.initial_write_bytes 4self.process_write_bytes_mb.set(write_bytes / (1024 * 1024)) 5
If this metric increases significantly, it indicates that data is being buffered to disk.
Comparison with Traditional Approach
For smaller files, the traditional download-then-upload approach performs better or at least on par with the streaming approach. This is due to:
- Single Large upload operation as compared to multiple smaller uploads
- Lower overhead of establishing connections and managing concurrency
- Optimal network utilization with a single TCP connection vs. multiple concurrent connections
However, as file sizes increase, the streaming method outperforms traditional methods significantly.
Memory usage remains constant regardless of file size, while traditional methods require disk space proportional to file size. The streaming approach also scales better with multiple large files, as it does not require disk space for intermediate storage. For larger files, the overhead of coordination becomes negligible compared to the parallelism gains.
Based on local tests generating files of various sizes, these are the expected results:
| File Size | Traditional Time | Streaming Time | Winner |
|---|---|---|---|
| 1-5GB | Faster | Slower | Traditional |
| 5-10GB | Similar | Similar | Tie |
| 10-20GB | Slower | Faster | Streaming |
| 20-50GB | Much Slower | Significantly Faster | Streaming |
Troubleshooting
Common issues and solutions:
High Process Write Bytes:
- Check if MinIO and app are on the same disk volume
- Verify that temporary directories aren't being used
- Monitor swap usage which may indicate memory pressure
Low Throughput:
- Increase concurrent workers or adjust chunk size
- Check network bandwidth between SFTP server and S3
- Verify S3 endpoint proximity to reduce latency
Memory Issues:
- Reduce chunk size or concurrent operations
- Monitor for memory leaks in long-running processes
SSH Host Key Errors:
- Set
known_hosts=Nonein connection parameters for testing - Implement proper host key verification for production
Conclusion
Streaming large files from SFTP to S3 without disk buffering provides significant advantages for data engineering workflows:
- Zero disk usage: Eliminates storage requirements and I/O bottlenecks
- Improved performance: Concurrent operations and pipelining reduce transfer times
- Better scalability: Memory-bounded operations handle files of any size
The implementation demonstrates how Python's asyncio capabilities, combined with proper resource management and monitoring, can build efficient production-ready data transfer solutions. By eliminating the traditional download-then-upload pattern, we achieve faster transfers while using minimal system resources.
Building efficient data pipelines requires both technical innovation and operational excellence. I help organizations optimize and scale their data infrastructure with solutions like streaming file transfers, ETL optimization, and cloud architecture. If you're looking to hire engineers who can build performant data pipelines, my hiring advisory services can connect you with senior data engineers experienced in building production-grade data transfer systems.
If you found this post useful or have any questions, feedback, or suggestions, please feel free to drop a comment below. I would love to hear from you about your own experiences with large file transfers and streaming architectures.
Enjoyed this post? Subscribe for more!
We respect your privacy. Unsubscribe at any time.